
ASPECT BASED SENTIMENT ANALYSIS
This post will implement the ABSA task in python on a Mobile product reviews dataset
Under guidance : Prof. Minu P Abraham(NMAMIT)
Introduction
Sentiment analysis is a very popular technique in Natural Language Processing. We can see it applied to get the polarity of social network posts, movie reviews, or even books.
However basic sentiment analysis can be limited, as we lack precision in the evoked subject.
Aspect-based sentiment analysis is a text analysis technique that breaks down text into aspects (attributes or components of a product or service), and then allocates each one a sentiment level (positive, negative or neutral).
If you thought sentiment analysis was pretty neat, then prepare to be blown away by this advanced text analysis technique, aspect-based sentiment analysis helps you get the most out of your data.
Imagine you have a large dataset of customer feedback from different sources such as NPS, customer satisfaction surveys, social media, and online reviews. Some positive, some negative and others that contain mixed feelings. You’d use sentiment analysis to automatically classify the polarity of each text, right? After all, it’s already proven to be a highly efficient tool.
But, what if you wanted to pick customer feedback apart, hone in on the details, get down to the nitty-gritty of each feedback for a more complete picture of your customers’ opinions?
Cue aspect-based sentiment analysis (ABSA). This technique can help businesses become customer-centric and place their customers at the heart of everything they do. It’s about listening to their customers, understanding their voice, analyzing their feedback and learning more about customer experiences, as well as their expectations for products or services.
Let’s take the example of reviews for a computer: how do we know what is good/bad ? Is it the keyboard, the screen, the processor?
The Aspect Based Sentiment Analysis method addresses directly that limitation. ABSA aim to look for the aspects term mentioned and gives the associated sentiment score.
Back to our computer example, in the following reviews:
-
“I absolutely love this bright retina screen”
-
“The butterfly keyboard is deceiving!”
With ABSA we would obtain a positive sentiment for the screen, and a negative sentiment for the keyboard. This is way more actionable from a business point of view.
But how can you get started with aspect-based sentiment analysis?
First, you’ll need to gather data, such as customer feedback, reviews, survey responses, social media and more. Next, you’ll need to analyze the information using aspect-based sentiment analysis. There are often hundreds or thousands of text entries from each source, so it would be far too time-consuming and repetitive to analyze them manually. And if you want to analyze information on a granular level, in the same way an aspect-based sentiment analysis does, it would be near impossible without machine learning.
This post will implement the ABSA task in python on a Mobile Phone reviews dataset. Similarly to the computer example, our model should return polarity contained in the sentences about the camera, battery, etc.
Overview
The ABSA model could be decomposed in three distinct main processes for an out-of-domain usecase:
-
Learning the Aspect Categories (SCREEN$Quality, PROCESSOR$Performance, etc.)
-
Finding the aspect words in sentences (retina screen, butterfly keyboard etc.) and classify to aspect category
-
Computing the polarity for each aspect in each entry
However, our mobile review usecase is what we call in-domain. That is, we already have defined the aspect categories related to the reviews. We then have a model composed of two distinct models: the Aspect Categories classifier and the Sentiment Model.


Step 1: Get the Aspect Terms
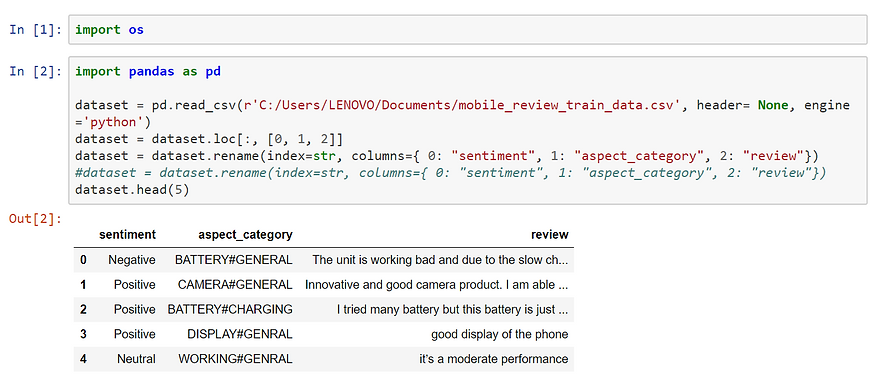
First things first, we want to load training data:
.png)
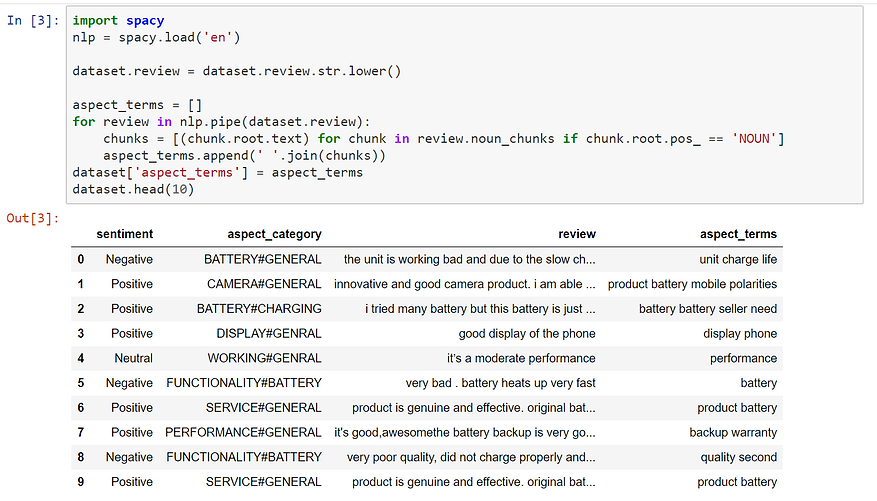
Now the data is ready to proceed to Aspect Terms extractions. First, we want to extract the Aspect Terms that we will feed to the Aspect Categories Classifier.
To do so we use the Noun chunk dependency parser of spaCy, a very efficient NLP library written in Cython. We don’t do that much text processing before, as certain operations modify the structure of the sentence and alter the spaCy detection.
.png)
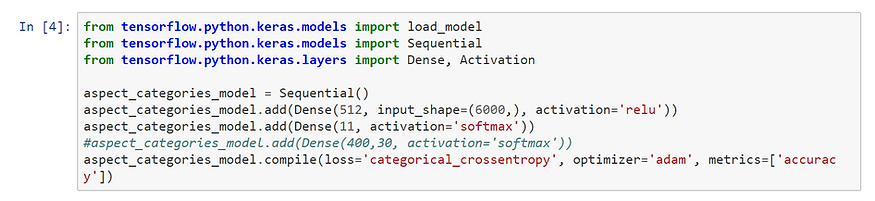
We can create our Aspect Categories Model! As a reminder, this model must find the Aspect Category given the Aspect Terms. To do so, we build a Convolutional Neural Network using the Keras library.
We use Sequential to initiate our model, and add layers to it:
-
The first layer is a dense layer with 512 nodes. The input shape is the shape of the word vectors (see explanation below). We use the relu activation function (often used for faster learning).
-
The second layer is our output layer. Its number of nodes is the number of outputs we want. The activation function is softmax because we want a probability distribution among the Aspect Categories. We have 11 Aspect Categories, so we want 11 nodes in the layer.
Step 2: Build the Aspect Categories Model
.png)
Using TensorFlow backend.
However we cannot directly feed words as string to the CNN, that is why we will encode our Aspect terms as vectors. This technique is called Word Embedding, and consists of representing a word by its representation as vector in a high dimensional space.
The Word Embedding technique we will use here is called Bag of Words and is very simple:
-
We create a matrix of occurrence of all the words in our vocabulary. For a vocabulary of size N and M sentences, we have an $S \times M$ matrix.
-
Each vector is then a one hot encoded representation according to the presence of the words
Hopefully, Keras has everything we need for this BoW word embedding.
.png)
Perfect, we also want to encode the aspect_category to dummy (binary) variables using Sklearn and Keras:
.png)
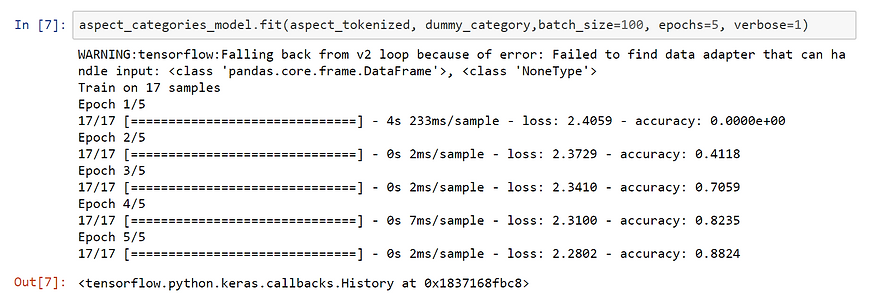
Learning time! Just one line of code to fit the model with input the encoded aspect terms and output the encoded aspect categories.
The number of epochs is kept relatively low to avoid overfitting.
.png)
Let’s try our Aspect Categories model on a new review. We have to do the same processing operations on that review and then predict using model.predict. And not forget to transform the output using inverse_encode.
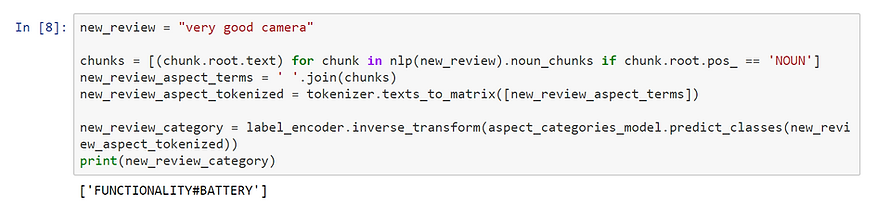.png)
This review is indeed about the Battery! We can go on to the most sentimental parts of this article :-)
Step 3: Get the Sentiment Terms
Now, we want to keep from our reviews only the words which can indicate if the expressed opinion is positive or negative.
We use spaCy once again, but this time we are going to use Part Of Speech Tagging to filter and keep only adjectives and verbs.
.png)
Step 4: Build the Sentiment Model
For the sentiment model, we use a very similar architecture than in step 2:
-
A dense layer that take as input word vectors of dimension 6000, with a relu activation function and 512 nodes.
-
An output layer with a softmax activation function to output probability distribution. This time with only 3 nodes because we want to predict positive, negative or neutral.
.png)
The input is going to be the feature sentiment_terms, but we need to use the same encoding process as for the aspect terms. This time we don’t have to create and fit a Tokenizer, because it already has been done on the entire review dataset in step 2.
The output is the feature sentiment, which requires an encoding to dummy variable. We need to create a new labelEncoder because we have only 3 categories, which is different from the 11 aspect categories.
.png)
Time to fit our second model ! The code is very similar here, and the CNN should fit the data even better considering than the classification is easier.
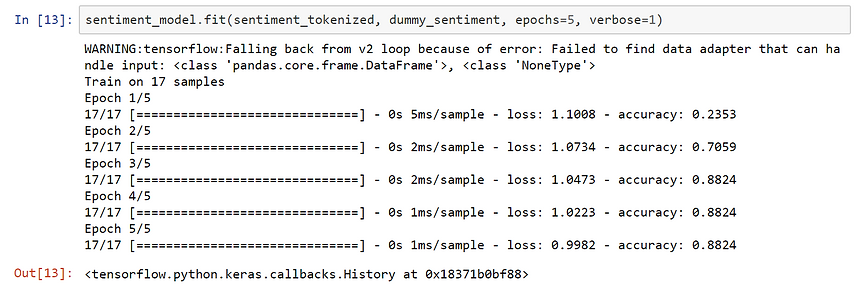.png)

Putting everything together
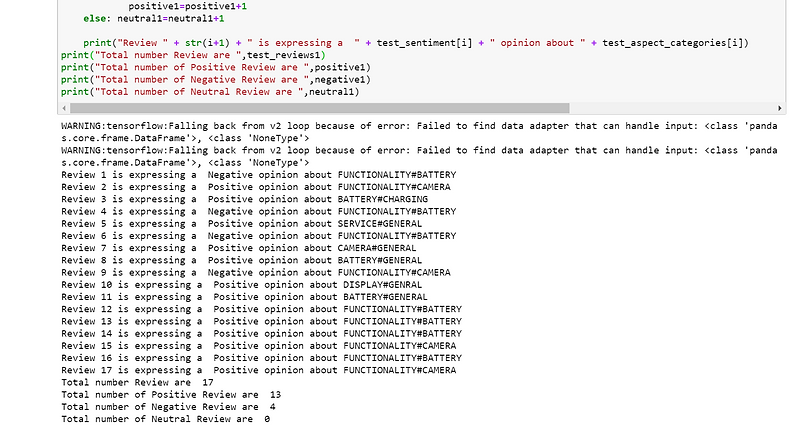
We now finally have both the Aspect Categories and the Sentiment models! Let’s define new reviews and apply our entire ABSA implementation:
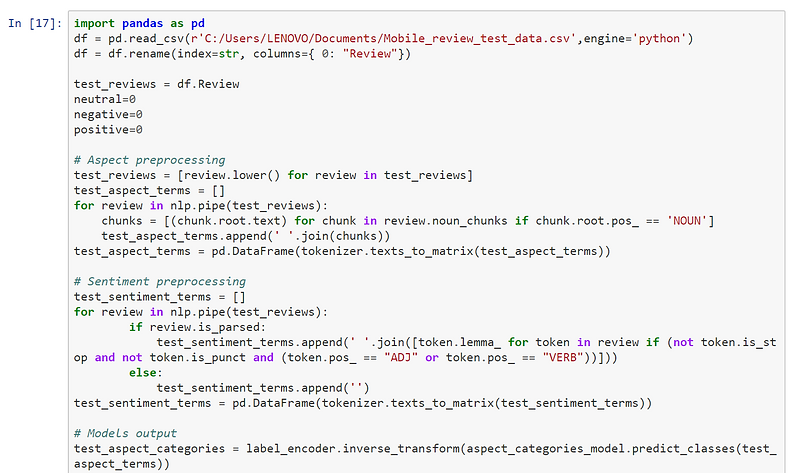.png)
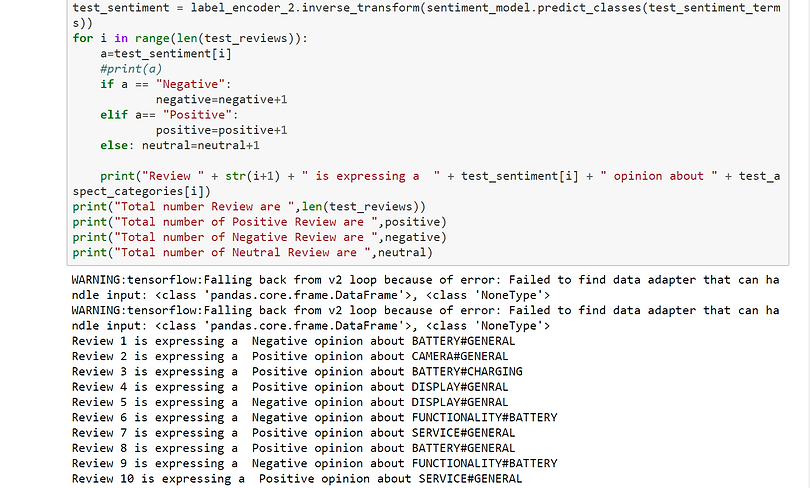.png)
.png)
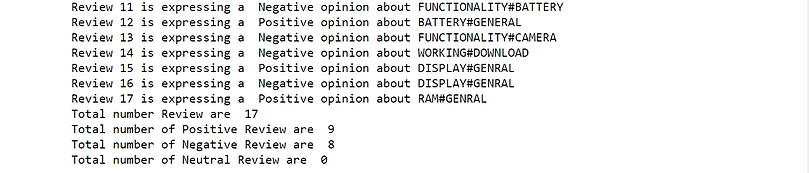
Running similar code again with different mobile review dataset for comparison
.png)
.png)
Comparing two product reviews for differentiation
.png)
We indeed identify the sentiment expressed in each review and the main topic addressed with precision, for each of the seventeen reviews!
